스트림은 요소들을 필터링 또는 매핑한 후 요소들은 수집하는 최종 처리 메소드인 collect()를 제공하고 있다.
이 메소드를 이용하면 필요한 요소만 컬렉션으로 담을 수 있고, 요소들을 그룹핑한 후 집계(리덕션)할 수 있다
필터링한 요소 수집
Stream의 collect(Collector<T, A, R> collector) 메소드는 필터링 또는 매핑된 요소들은 새로운 컬렉션에 수집하고 리턴

매개값인 Collector(수집기) 어떤 요소를 어떤 컬렉션에 수지 할 것인지를 결정
Collector 의 타입 파라미터 T는 요소이고, A는 누적기(accumulator)이다, 그리고 R은 요소가 저장될 컬렉션이다,
풀어서 해석하면 T요소를 A누적기가 R에 저장한다는 의미 이다.
Collector의 구현 객체는 다음과 같이 Collector 클래스의 다양한 정적 메소드를 이용해서 얻을 수 있다.
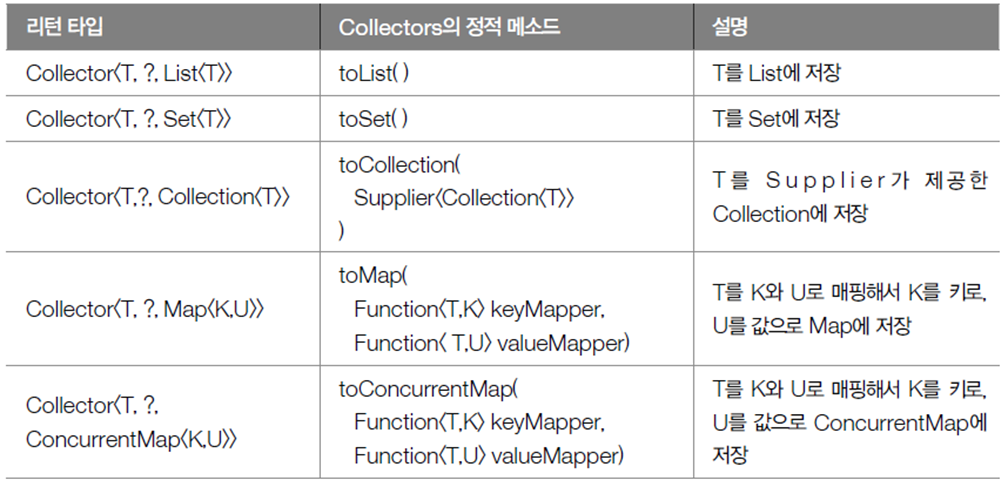
리턴값인 Collector를 보면 A(누적기)가 ?로 되어 있는데, 이것은 Collector 가 R(컬렉션)에 T(요소)를 저장하는 방법을 알고있어 A(누적기)가 필요없기 때문이다.
Map과 ConcurrrentMap의 차이점은 Map은 스레드에 안전하지 않고, ConcurrentMap은 스레드에 안전하다
멀티스레드 환경에서 사용하려면 ConcurrentMap을 얻는 것이 좋다
Stream<Student> totalStream = totalList.stream();
Stream<Student> maleStream = totalStream.filter(s->s.getSex() == Student.Sex.MALE);
Collector<Student, ?, List<Student>> Collector = Collectors.toList();
List<Student> maleList = maleStream.collect(collector);1. 전체 학생 List에서 Stream 을 얻는다,
2. 남학생만 필터링해서 Stream을 얻는다.
3. List에 Student를 수집하는 Collector를 얻는다
4. Stream에서 collect() 메소드로 Student를 수집해서 새로운 List를 얻는다.
package Stream;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
import com.ho.Main;
public class ToListExample {
public static void main(String[] args) {
List<Student> totalList = Arrays.asList(new Student("홍길동", 10), new Student("임꺽정", 20), new Student("유관순", 30),
new Student("안중근", 40));
// 10점 이상 리스트 생성
List<Student> highScoreList = totalList.stream()
.filter(student -> student.getScore() >= 10).collect(Collectors.toList());
highScoreList.stream().forEach(student -> System.out.println(student.getName()));
// 10 점 이상 리스트 해쉬 셋 생성 (중복 제거)
Set<Student> hiStudents = totalList.stream()
.filter(student -> student.getScore() >= 10).collect(Collectors.toCollection(HashSet::new));
hiStudents.stream().forEach(student -> System.out.println(student.getName()));
}
}
사용자 정의 컨테이너에 수집하기
List, Set Map 과 같은 컬렉션이 아니라 사용자 정의 컨테이너 객체에 수집하는 방법에 대해 알아보기로 하자
스트리은 요소들을 필터링, 매핑해서 사용자 정의 컨터이너 객체에 수집할 수 있도록 Collect () 메소드를 추가적으로 제공
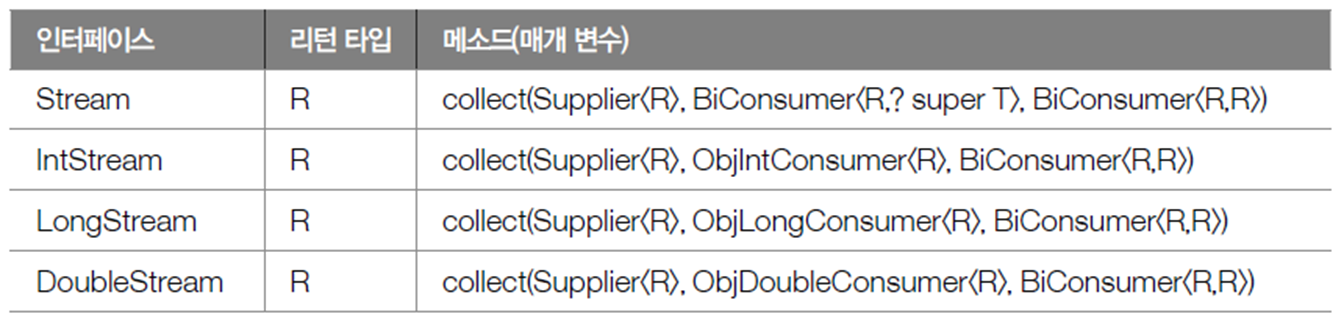
- 첫 번째 Supplier는 요소들이 수집될 컨테이너 객체(R)를 생성하는 역할을 한다
순차 처리(싱글 스레드) 스트림에서는 단 한 번 Supplier가 실행되고 하나의 컨테이너 객체를 생성한다.
병렬처리 (멀티 스레드) 스트림에 서는 여러번 Supplier 가 실행되고 스레드별로 여러개의 컨테이너 객체를 생성한다.
하지만 최종적으로 하나의 컨테이너 객체로 결합된다.
- 두번째 XXXConsummer는 컨터이네 개체(R)에 요소(T)를 수집하는 역할을 한다. 스트림에서 요소를 컨터이너에 수집할 때마다 XXXConsumer가 실행된다
- 세번째 BiConsumer는 컨테이너 객체(R)를 결합하는 역할을 한다. 순차 처리 스트림에서는 호출되지 않고,
병렬 처리 스트림에서만 호출되어 스레드 별로 생성된 컨테이너 개체를 결하해서 최종 컨테이너 객체를 완성한다.
리턴 타입 R은 요소들이 최종 수집된 컨테이너 객체이다.
순차 처리 스트림에서는 리턴 객체가 첫번째 Supplier가 생성한 객체지만 병렬 처리 스트림에서는 최조열합된 컨테이너 객체가 된다.
병렬처리는 다음 절에서 살펴보기로 하고 여기서는 순차처리를 이용해서 사용자 정의 객체에 요소를 수집하는 것을 살펴보기로 하자.
학생들 중에서 남한 생만 수집하는 MaleStudent 컨테이너가 다음과 같이 정의 되어 있다고 가정해보자
package Stream;
import java.util.ArrayList;
import java.util.List;
public class MaleStudent {
private List<Student> list; // 요소를 저장할 컬렉션
public MaleStudent() {
list = new ArrayList<Student>();
System.out.println("[" + Thread.currentThread().getName() + "] MaleStudent()");
}
public void accumlate(Student student) { // 요소를 수집하는 메소드
list.add(student);
System.out.println("[" + Thread.currentThread().getName() + "] accumlate()");
}
public void combine(MaleStudent other) {
list.addAll(other.getList());
System.out.println("[" + Thread.currentThread().getName() + "] combine()");
}
public List<Student> getList() {
return list;
}
}
list 필드는 남학생들이 수집된 필드 이다.
MaleStudent() 생성자가 몇 번 호출되었는지 확인 하기 위해 호출한 스레드의 이름과 함께 생성자 이름을 출력한다.
순차 처리 스트림에서 MaleStudent() 생성자는 딱 한 번 호출되고, 하나의 MaleStudent 객체만 생성된다.
accumulate() 메소드는 매개값으로 받은 Student를 list필드에 수집하는데,
accumulate()메소드가 몇 번 실행되었는지 확인 하기 위해 호출한 스레드의 이름과 함께 메소드 이름을 출력해 보았다.\
combine() 메소드는 병렬처리스트림을 사용할때 다른 MaleStudent와 결합할 목적으로 실행 된다.
순차처리 스트림에서는 호출되지 않기 때문에 정의할 필요가 없다고 생각되지만,
collect() 메소드의 세 번째 매개값인 Biconsumer를 생성하기 위해서는 필요하다.
package Stream;
import java.util.Arrays;
import java.util.List;
public class MaleStudentExample {
public static void main(String[] args) {
List<Student> totalList = Arrays.asList(new Student("홍길동", 10, "MALE"), new Student("홍길동", 10, "MALE"),
new Student("홍길동", 10, "MALE"));
MaleStudent maleStudent = totalList.stream().filter(s->s.getSex().equals("MALE")).collect(MaleStudent :: new, MaleStudent :: accumlate, MaleStudent :: combine);
maleStudent.getList().stream().forEach(s->System.out.println(s.getName()));
}
}1. 전체 학생 List 에서 Stream을 얻는다.
2. 남학생만 필터링해서 Stream을 얻는다.
3. MaleStudent를 공급하는 Supplier를 얻는다.
4. MaleStudent와 Student를 매개값으로 받아서 MaleStudent 의 accumulate()메소드로 Student를 수집하는 BiConsumer를 얻는다.
5. 두개의 MaleStudent를 매개값으로 받아 combine() 메소드로 결합하는 BiConsumer 를 얻는다
6. supplier가 제공하는 MaleStudent를 얻는다.
싱글스레드에서는 combiner는 사용되지 않는다.
순차처리를 담당한 스레드는 main 스레드임을 알수 있다.
MaleStudent() 생성자가 딱 한 번 호출되었기 때문에 한 개의 MaleStudent 객체가 생성되었고,
accumulate()가 3번 호출 되었기 때문에 요소들이 3번 수집되었다. 그래서 collect()가 리턴한 최종 MaleStudent에는 남학생 3명이 저장되어있는것을 볼수 있다.
요소를 그룹핑해서 수집
collect() 메소드는 단순히 요소를 수집하는 기능 이외에 컬렉션의 요소들을 그룹핑해서 Map 객체를 생성하는 기능도 제공
collect()를 호출할 때 Collectors 의 groupingBy() 또는 groupingByConcurrent()가 리턴하는 Collector를 매개값을로 대입하면 된다.
groupingBy()는 스레드에 안전하지 않은 Map을 생성하지만, groupingByConcurrent()는 스레드에 안전한 ConcurrentMap을 생성한다

다음 코드는 학생들을 성별로 그룹핑하고 나서, 같은 구룹에 속하는 학생 List를 생성한 후,
성별을 키로, 학생 List를 값으로 갖는 Map을 생성한다,
collect()의 매개값으로 groupingBy(Function<T,K> classifier)를 사용하였다
Stream<Student> totalStream = totalList.Stream();
Function<Student, Student.Sex> classfier = Student :: getSex;
Collector<Student, ?, Map<Student.Sex, List<Student>>> collector = Collectors.gruopingBy(classifier);
Map<Student.Sex, List<Student>> mapBySex = totatlStream.collect(collector);1. 전체 학생 List 에서 Stream 을 얻는다
2. Stundent 를 Student.Sex로 매핑하는 Function을 얻는다.
3. Student.Sex가 키가 되고, 그룹핑된 List<Student>가 값인 Map을 생성하는 Collector를 얻는다
4. Stream의 collect() 메소드로 Student를 Student.Sex 별로 그룹핑해서 Map을 얻는다.
상기 코드에서 변수를 생략하면 아래와 같이 간단하게 작성
Map<Studnet.Sex, List<Student>> mapBySex = totalList.stream().collect(Collectors.groupingBy(Student :: getSex));
다음 코드는 학생들을 거주 도시별로 그룹핑 하고 나서, 같은 그룹에 속하는 학생들의 이름 List를 생성한 후
거주 도시를 키로, 이름 List를 값으로 갖는 Map을 생성한다. collect()의 매개값으로 groupingBy(Function<T,K> classsfier,Collector<T,A,D> collector)를 사용하였다.
Stream<Student> totalStream = totalList.Stream();
Function<Student, Student.City> classifier = Student :: getCity;
Function<Student, String> mapper = Student::getName;
Collector<String, ? , List<String>> collector1 = Collectors.toList();
Collector<Student, ? ,List<String>> collector2 = Collectors.mapping(mapper, collector1)
Collector<Student, ?, Map<Student.City, List<Student>>> collector3 = Collectors.gruopingBy(classifier, collector2);
Map<Student.City, List<Student>> mapByCity = totatlStream.collect(collector3);1. 전체 학생 List에서 Stream을 얻는다.
2. Student를 Student.City로 매핑하는 Function을 얻는다
3-5 Student의 이름을 List에 수집하는 Collector를 얻는다.
Student를 이름으로 매핑하는 Function을 얻는다
이름을 List에 수집하는 Collector를 얻는다.
Collectors의 mapping() 메소드로 Student를 이름으로 매핑하고 이름을 List 수집하는 Collector를 얻는다
6 Student.City 가 키이고, 그룹핑된 이름 List가 값인 Map을 생성하는 Collector를 얻는다
7 Stream의 collect 메소드로 Student를 Student.City 별로 그룹핑 해서 Map을 얻는다
아래와 같이 같단하게 작성할수 있다.
Map<Student.City, List<String>> mapByCity = totalList.stream().collect(Collectors.gruopingBy(Student::getCity, Collectors.mapping(Student::getName, Collectors.toList()))));위와 동일한 코드지만 TreeMap 객체를 생성하도록 groupingBy(Function<T,K> classifier, Supplier<Map<K,D>> mapFactory, Collector<T,A,D> collector)를 사용하였다.
Map<Student.City, List<String>> mapByCity = totalList.stream().collect(Collectors.groupingBy(Student::getCity,TreeMap::new,Collectors.mapping(Student::getName. Collectors.toList())));
package Stream;
public class reMakeStudent implements Comparable<Student> {
public enum Sex {
MALE, FEMALE
}
public enum City {
Seoul, Pusan
}
private String name;
private int score;
private Sex sex;
private City city;
public reMakeStudent(String name, int score) {
this.name = name;
this.score = score;
}
public reMakeStudent(String name, int score, Sex sex) {
this.name = name;
this.score = score;
this.sex = sex;
}
public reMakeStudent(String name, int score, Sex sex, City city) {
this.name = name;
this.score = score;
this.sex = sex;
this.city = city;
}
public City getCity() {
return city;
}
public void setCity(City city) {
this.city = city;
}
public Sex getSex() {
return sex;
}
public void setSex(Sex sex) {
this.sex = sex;
}
public String getName() {
return name;
}
public int getScore() {
return score;
}
@Override
public int compareTo(Student o) {
// TODO Auto-generated method stub
return Integer.compare(score, o.getScore());
}
}package Stream;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class GroupingByExample {
public static void main(String[] args) {
List<reMakeStudent> totalList = Arrays.asList(
new reMakeStudent("홍길동", 10, reMakeStudent.Sex.MALE, reMakeStudent.City.Seoul),
new reMakeStudent("김동주", 14, reMakeStudent.Sex.FEMALE, reMakeStudent.City.Pusan),
new reMakeStudent("하징더", 12, reMakeStudent.Sex.FEMALE, reMakeStudent.City.Pusan),
new reMakeStudent("오쟝가", 11, reMakeStudent.Sex.MALE, reMakeStudent.City.Seoul));
Map<reMakeStudent.Sex, List<reMakeStudent>> mapBySex = totalList.stream()
.collect(Collectors.groupingBy(reMakeStudent::getSex));
System.out.println("남학생");
mapBySex.get(reMakeStudent.Sex.MALE).stream().forEach((s) -> System.out.println(s.getName() + " "));
System.out.println();
System.out.println("여학생");
mapBySex.get(reMakeStudent.Sex.FEMALE).stream().forEach((s) -> System.out.println(s.getName() + " "));
System.out.println();
Map<reMakeStudent.City, List<String>> mapByCity = totalList.stream().collect(Collectors
.groupingBy(reMakeStudent::getCity, Collectors.mapping(reMakeStudent::getName, Collectors.toList())));
System.out.println("서울");
mapByCity.get(reMakeStudent.City.Seoul).stream().forEach(s -> System.out.println(s + " "));
System.out.println();
System.out.println("부산");
mapByCity.get(reMakeStudent.City.Pusan).stream().forEach(s -> System.out.println(s + " "));
}
}
그룹핑 후 매핑 및 집계
Collectors.groupingBy() 메소드는 그룹핑 후, 매핑이나 집계(평균, 카운팅, 연결, 최대, 최소, 합계)를 할 수 있도록
두 번째 매개값으로 Collector를 가질 수 있다.
이전 예제에서 그루핍된 학생 객체를 학생 이름으로 매핑하기 위해 mapping()메소드로 Collector를 얻었다
Collector는 mapping() 메소드 이외에도 집계를 위해 다양한 Collector를 리턴하는 다음과 같은 메소드를 제공하고 있다.

다음 코드는 학생들을 성별로 그룹핑한 다음 같은 그룹에 속하는 학생들의 평균 점수를 구하고,
성별을 키로, 평균 점수를 값으로 갖는 Map을 생성한다.
Stream<Student> totalStream = totalList.stream();
Function<Student, Student.Sex> classifier = Student::getSex;
ToDoubleFunction<Student> mapper = Student::getScore;
Collector<Student, ? ,Double> collector1 = Collectors.averagingDouble(mapper);
Collector<Student, ? , Map<Student.Sex, Double>> collect2 = Collectors.groupingBy(classifier, collector1);
Map<Student.Sex, Double> mapBySex = totalStream.collect(collect2);1. 전체 학생 List에서 Stream을 얻는다
2. Student를 Student.sex 로 매핑하는 Function을 얻는다
3. Student를 점수로 매핑하는 ToDoubleFunction을 얻는다
4 학생 점수의 평균을 산출하는 Collector를 얻는다
5 Student.Sex가 키이고, 평균 점수 Double이 값인 Map을 생성하는 Collector를 얻는다
6. Stream의 collect() 메소드로 Student를 Student.Sex 별로 그룹핑해서 Map을 얻는다
위 코드에서 아래와 같이 간단하게 작성할수 있다.
Map<Student.Sex,Double> mapBySex = totalList.stream().collect(Collectors.groupingBy(Student::getSex, Collectors.averagingDouble(Studemt::getScore)));
다음 코드는 학생들을 성별로 그룹핑한 다음 같은 그룹에 속하는 학생이름을 쉼표로 구분해서 문자열로 만들고, 성별을 키로, 이름 문자열을 값으로 갖는 Map을 생성한다.
Map<Student.Sex, String> mapByName = totalList.stream().collect(Collectors.groupingBy(Student::getSex,Collectors.mapping(Student::getName,Collectors.joining(","))));package Stream;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collector;
import java.util.stream.Collectors;
public class GroupingAndReductionExample {
public static void main(String[] args) {
List<reMakeStudent> totalList = Arrays.asList(
new reMakeStudent("홍길동", 10, reMakeStudent.Sex.MALE),
new reMakeStudent("김수애", 12, reMakeStudent.Sex.FEMALE),
new reMakeStudent("신용권", 10, reMakeStudent.Sex.FEMALE),
new reMakeStudent("박수미", 12, reMakeStudent.Sex.MALE));
// 성별로 평균 점수를 저장하는 Map 얻기
Map<reMakeStudent.Sex, Double> mapBySex = totalList.stream().collect(
Collectors.groupingBy(reMakeStudent::getSex, Collectors.averagingDouble(reMakeStudent::getScore)));
System.out.println("남한색 평균 점수" + mapBySex.get(reMakeStudent.Sex.MALE));
System.out.println("여한색 평균 점수" + mapBySex.get(reMakeStudent.Sex.FEMALE));
// 성별을 쉼표로 구분한 이름을 저장하는 Map 얻기
Map<reMakeStudent.Sex, String> mapByName = totalList.stream().collect(Collectors.groupingBy(
reMakeStudent::getSex, Collectors.mapping(reMakeStudent::getName, Collectors.joining(","))));
System.out.println("남학생 전체 이름 " + mapByName.get(reMakeStudent.Sex.MALE));
System.out.println("여학생 전체 이름 " + mapByName.get(reMakeStudent.Sex.FEMALE));
}
}'Back-end > 이것이 자바다[신용권 한빛미디어]' 카테고리의 다른 글
| IO 패키지 소개 및 입력, 출력 스트림 [IO 기반 입출력 및 네트워킹] (0) | 2022.10.03 |
|---|---|
| 병렬 처리 (0) | 2022.09.29 |
| 커스텀 집계(reduce()) (0) | 2022.06.25 |
| 기본 집계(sum(), count(), average(), max(), min()) (0) | 2022.06.03 |
| 루핑(peek(), forEach()), 매칭 (allMatch(), anyMatch(), noneMatch()) (0) | 2022.06.02 |