병렬 처리(Parallel Operation)란 멀티코어 CPU 환경에서 하나의 작업을 분할해서 각각의 코어가 병력적으로 처리하는 것을 말하는데, 병렬 처리의 목적은 작업 처리 시간을 줄이기 위한 것이다
자바 8부터 요소를 병렬 처리할 수 있도록 하기 위해 병렬 스트림을 제공하기 때문에 컬렉션(배열)의 전체 요소 처리 시간을 줄여준다
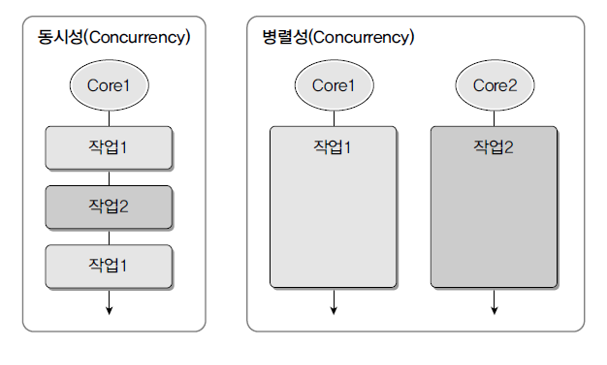
동시성(Concurrency)과 병렬성(Parallelism)
멀티 스레드는 동시성(Concurrency) 또는 병렬성(Parallelism)으로 실행되기 때문에 이 용어 들에 대해 정확히 이해하는 것이 좋다.
이 둘은 멀티 스레드의 동작 방식이라는 점에서는 동일하지만 서로 다른 목적을 가지고 있다
동시성은 멀티 작업을 위해 멀티 스레드가 번갈아가며 실행하는 성질을 말하고
병렬성은 멀티 작업을 위해 멀티 코어를 이용해서 동시에 실행하는 성질을 말한다.
병렬성은 데이터 병렬성(Data parallelism)과 작업 병렬성(Task parallelism)으로 구분할 수 있다.
싱글 코어 CPU를 이용한 멀티 작업은 병렬적으로 실행되는 것 처럼 보이지만,
사실은 번갈아가며 실행하는 동시성 작업이다.
번갈아가며 실행하는 것이 워낙 빠르다 보니 병렬성으로 보일 뿐이다.
데이터 병렬성
데이터 병렬성은 전체 데이터를 쪼개어 서브 데이터들로 만들고
이 서브 데이터들을 병렬 처리해서 작업을 빨리 끝내는 것을 말한다
자바 8에서 지원하는 병렬 스트림은 데이터 병렬성을 구현한 것읻
멀티 코어의 수만큼 대용량 요소를 서브 요소들로 나누고, 각각의 서브 요소들을 분리된 스레드에서 병렬 처리시킨다.
예를 들어 쿼드 코어(Quad Core) CPU일 경우 4개의 서브 요소들로 나누고, 4개의 스레드가 각각의 서브 요소들을 병렬 처리한다
작업 병렬성
작업 병렬성은 서로 다른 작업을 병렬 처리하는 것은 말한다.
작업 병렬성의 대표적인 예는 웹서버(Web Server)이다, 웹서버는 각각의 브라우저에서 요청한 내용을 개별 스레드에서 병렬로 처리한다.
포크 조인(ForkJoin) 프레임 워크
병렬 스트림은 요소들을 병렬 처리하기 위해 포크 조인(ForkJoin) 프레임 워크(Framework)를 사용한다.
병렬 스트림을 이용하면 런타임 시에 포크조인 프레임워크가 동작하는데,
포크 단계에서는 전체 데이터를 서브 데이터로 분리한다. 그러고 나서 서브 데이터를 멀티 코어에서 병렬로 처리한다.
조인 단계에서는 서브 결과를 결합해서 최종 결과를 만들어 낸다.
예를 들어 쿼드 코어 CPU에서 병렬 스트림은 작업을 처리할 경우,
스트림의 요소를 N 개라고 보았을 때 포크 단계에서는 전체 요소를 4등분 한다.
그리고 1 등분씩 개별 코어에서 처리하고 조인 단계에서는 3번의 결합 과정을 거쳐 최종 결과를 산출한다
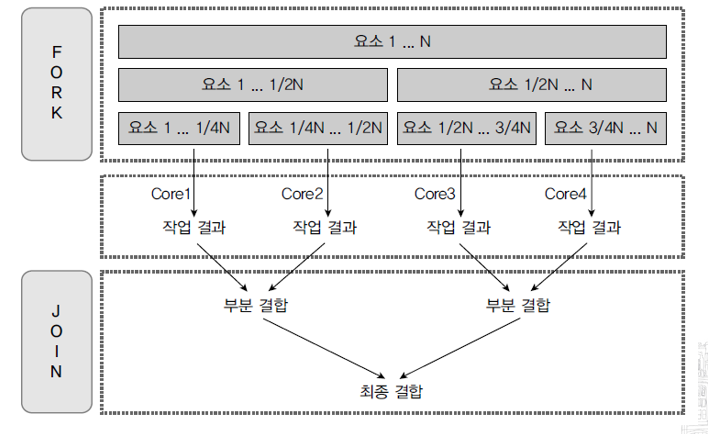
병렬 처리 스트림은 실제로 포크단계에서 차례대로 요소를 4등분 하지 않는다
이해하기 쉽도록하기 위해 위 그림은 차례대로 4등분했지만, 내부적으로 서브요소를 나누는 알고리즘이 있다.
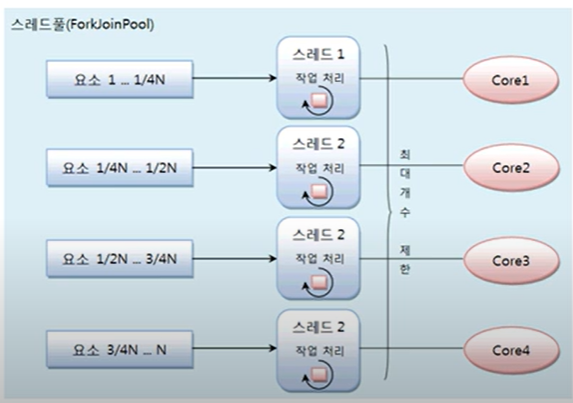
포크조인 프레임워크는 포크와 조인 기능 이외에 스레드풀인 ForkJoinPool을 제공한다.
각각의 코어에서 서브 요소를 처리하는 것은 개별 스레드가 해야 하므로 스레드 관리가 필요하다.
포크조인 프레임워크는 ExecutorService 의 구현 객체인 ForkJoinPool을 사용해서 작업스레드를 관리한다
병렬 스트림 생성
병렬 처리를 위해 코드에서 포크조인 프레임 워크를 직접 사용할 수는 있지만,
병렬 스트림을 이용할 경우 백그라운드에서 포크조인 프레임워크가 사용되기 때문에
개발자는 매우 쉽게 병렬 처리를 할 수 있다.
병렬 스트림은 다음 두가지 메소드로 얻을수 있다
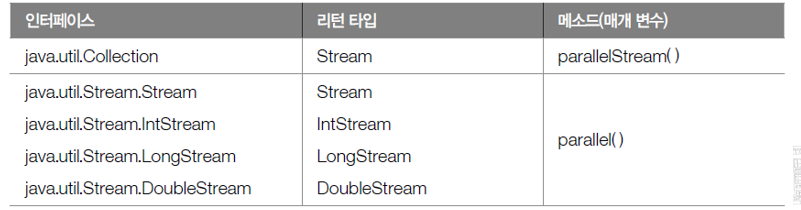
parallelStream() 메소드는 컬렉션으로부터 병렬 스트림을 바로 리턴한다
parallel() 메소드는 순차 처리 스트림을 병렬 처리 스트림으로 변환해서 리턴한다.
어떤 과정으로 병렬 스트림을 얻더라도 이후 요소 처리 과정은 병렬 처리된다.
내부적으로 전체요소를 서브 요소들로 나누고, 요소들을 개별 스레드가 처리한다.
서브 처리 결과가 나오면 결합해서 마지막으로 최종처리 결과를 리턴한다.
내부적인 동작을 확인하려면 사용자 정의 컨터이너에 수집하기 병렬 스트림으로 수정해서 실행 해보면 된다
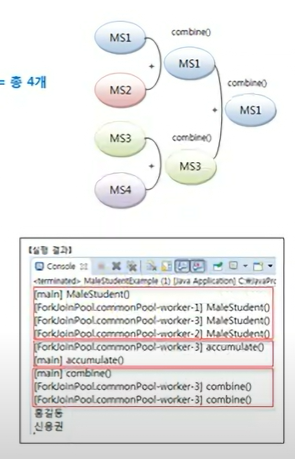
MaleStudent maleStudent = totalList.stream().filter( s-> s.getSex() == Studemt.Sex.MALE)
.collect(MaleStudent::new, MaleStudent::accumulate,MaleStudent::combine);전체 학생 목록에서 stream() 메소드로 순차 처리 스트림을 얻었기 때문에 MaleStudent 객체는 하나만 생성되고,
남학생을 MaleStudent에 수집하기 위해 accumulate()가 호출된다.
combine()메소드는 전혀 호출 되지 않았는데, 그 이유는 순차 처리 스트림으로 결합할 서브 작업이 없기 때문이다.
이코드를 병렬 처리 스트림으로 변경하면 다음과 같다
MaleStudent maleStudent = totalList.parallelstream().filter( s-> s.getSex() == Studemt.Sex.MALE)
.collect(MaleStudent::new, MaleStudent::accumulate,MaleStudent::combine);
단순히 stream() 메소드 호출이 paralleStream() 메소드 호출로 변경되었지만 내부동작은 다음과 같은 순서로 전혀 다르게 진행 된다
1. 쿼드코어 CPU에서 실행된다면 전체 요소는 4개의 서브요소로 나눠지고, 4개의 스레드가 병렬 처리한다,
각 스레드는 서브요소를 수집해야 하므로 4개의 MaleStudent 객체를 생성하기 위해 collect() 의 첫 번째 메소드 참조인 MaleStudent::new 를 4번 실행 시킨다
2. 각 스레드는 MaleStudent 객체에 남학생 요솔를 수집하기 위해 두번째 메소드 참조인 MaleStudent :: accumulate 를 매번 실행 시킨다.
3. 수집이 완료된 4개의 MalStudent는 3번의 결합으로 최종 MaleStudent 가 만들어 질수 있으로므로 세번째 메소드 참조인 MaleStudent:: combine 이 3번 실행된다
package Stream;
import java.util.Arrays;
import java.util.List;
public class ParallelStreamMaleStudentExample {
public static void main(String[] args) {
List<Student> totalList = Arrays.asList(new Student("홍길동", 10, "MALE"), new Student("홍길동", 10, "MALE"),
new Student("홍길동", 10, "MALE"));
MaleStudent maleStudent = totalList.parallelStream().filter(s -> s.getSex().equals("MALE")).collect(MaleStudent::new,
MaleStudent::accumlate, MaleStudent::combine);
maleStudent.getList().stream().forEach(s -> System.out.println(s.getName()));
}
}
실행 결과를 보면 main 스레드와 ForkJoinpool 에서 3개의 스레드가 사용되어 총 4개의 스레드가 동작한다.
이것은 필자의 컴퓨터가 쿼드코어 CPU를 사용하기 떄문이다.
각각의 스레드가 하나의 서브 작업이라고 본다면 총 4개의 서브작업으로 분리되었다고 생각하면 된다.
각 서브 작업은 남학생을 누적시킬 MaleStudent 객체를 별도로 생성하기 때문에 MaleStudent() 생성자가 4번 실행 되었다
하지만 전체 학생 중에서 낙학생이 2명 밖에 없으므로 accmulate()는 2번 밖에 호출되지 않았다.
누적이 완료된 4개의 MaleStudent 객체는 3번의 결합으로 최종 MaleStudent가 만들어 지므로 combine() 메소드가 3번 호출 되었다.
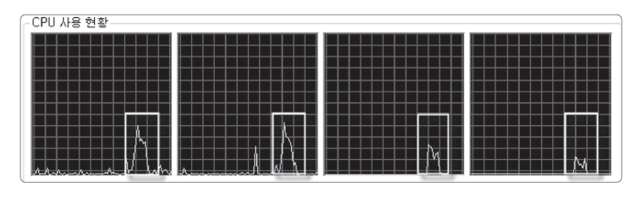
학생수를 100명으로 늘리고 쿼드코어 CPU에서 테스트한 결과를 보여준다. 4개의 코어가 병렬적으로 요소를 처리하고 있는 모습을 볼수 있다
병렬 처리 성능
스트림 병렬 처리가 스트림 순차 처리보다 항상 실행 성는이 좋다고 판단해서는 안된다.
병렬 처리에 영향을 미치는 다음 3개지 요인을 잘 살펴보아야 한다.
요소의 수와 요소당 처리 시간
컬렉션에 요소의 수가 적고 요소당 처리 시간이 짧으면 순차처리가 오히려 병렬 처리보다 빠를 수 있다.
병렬 처리는 스레드풀 생성, 스레드 생성이라는 추가적인 비용이 발생하기 때문이다
스트림 소스의 종류
ArrayList, 배열은 인덱스로 요소를 관리하기 때문에 포크 단계에서 요소를 쉽게 분리할수 있어 병렬 처리 시간이 절약된다
반명에 HashSet, TreeSet 은 요소 분리가 쉽지않고 , LinkedList 역시 링크를 따라가야 하므로 요소 분리가 쉽지 않다. 따라서 이소스들은 ArrayList, 배열보다는 상대적으로 병렬 처리가 늦다
코어(Core)의 수
싱글 코어 CPU일 경우에는 순차 처리가 빠르다. 병렬 스트림을 사용할 경우 스레드의 수만 증가하고 동시성 작업으로 처리되기 때문에 좋지 못한 결과를 준다. 코어의 수가 많으면 많을 수록 병렬 작업 처리 속도는 빨라진다.
다음 예제는 work() 메소드의 실행 시간(요소당 처리 시간)을 조정함으로써 순차 처리와 병렬 처리 중 어떤 것이 전체요소를 빨리 처리하는지 테스트 한다.
package Stream;
import java.util.Arrays;
import java.util.List;
public class SequencialVsParallelExample {
// 요소 처리
public static void work(int value) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
}
}
// 순차 처리
public static long testSequencial(List<Integer> list) {
long start = System.nanoTime();
list.stream().forEach((a) -> work(a));
long end = System.nanoTime();
return end - start;
}
// 순차 처리
public static long testParallel(List<Integer> list) {
long start = System.nanoTime();
list.parallelStream().forEach((a) -> work(a));
long end = System.nanoTime();
return end - start;
}
public static void main(String[] args) {
// 소스컬렉션
List<Integer> list = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9);
// 순차 스트림 처리 시간 구하기
long timeSequencial = testSequencial(list);
// 병렬 스트림 처리 시간 구하기
long timeParallel = testParallel(list);
System.out.println("성능 테스트 결과 " + (timeSequencial < timeParallel ? "순차 처리" : "병럴 처리") + "가 더 빠름");
}
}이 예제의 실행 결과는 work()의 요소 처리 시간에 따라 달라진다.
필자가 진행해본 결과 Thread.sleep(10) 으로 실행하면 순차처리가 더 빨랐다.
그렇기 때문에 실제 작업 내용을 작성한 후에는 순차 처리와 병렬 처리 중 어떤 처리가 유리한지 테스트해 보아야 한다.
다음 예제는 스트림 소스가 ArrayList인 경우와 LinkendList일 경우 대용량 데이터의 병렬 처리 성능을 테스트한 것이다.
백만 개의 Integer 객체를 각각 ArratList와 LinkedList에 저장하고 테스트 하였다.
실행 결과는 ArrayList가 빠른 실행 성능을 보였다. 하지만 요소의 개수가 적을 경우에는 LinkedList가 더 빠른 성능을 보였다. 워밍업을 둔 이유는 실행 준비 과정에서의 오차를 줄이기 위해서 이다
'Back-end > 이것이 자바다[신용권 한빛미디어]' 카테고리의 다른 글
| IO 패키지 소개 및 입력, 출력 스트림 [IO 기반 입출력 및 네트워킹] (0) | 2022.10.03 |
|---|---|
| 수집(collect()) (1) | 2022.09.22 |
| 커스텀 집계(reduce()) (0) | 2022.06.25 |
| 기본 집계(sum(), count(), average(), max(), min()) (0) | 2022.06.03 |
| 루핑(peek(), forEach()), 매칭 (allMatch(), anyMatch(), noneMatch()) (0) | 2022.06.02 |